一、首先我们安装elasticsearch
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。
我们要下载的是 elasticsearch-rtf, Elasticsearch-RTF是针对中文的一个发行版,即使用最新稳定的elasticsearch版本,并且帮你下载测试好对应的插件,如中文分词插件等,目的是让你可以下载下来就可以直接的使用(虽然es已经很简单了,但是很多新手还是需要去花时间去找配置,中间的过程其实很痛苦),当然等你对这些都熟悉了之后,你完全可以自己去diy了,跟linux的众多发行版是一个意思。
下载地址:github https://github.com/medcl/elasticsearch-rtf
1.运行环境
a.JDK8+
b.系统可用内存>2G
这里如何安装jdk,我不做过多解释,百度上太多教程了。
2.安装elasticsearch
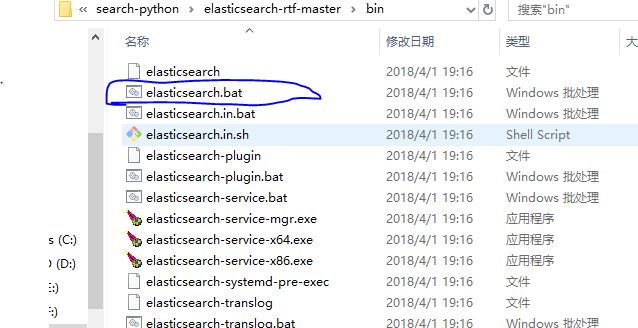
下载之后运行图中的 elasticsearch.bat 文件
3.安装 elasticsearch-head 插件
安装elasticsearch-head插件需要nodejs的支持,所以此处讲解一下安装nodejs步骤
可以访问 https://blog.csdn.net/mjlfto/article/details/79772848 里面有详细的步骤。